
In this second part of my Continuous Futures mini-series, we will convert our Sierra Chart continuous futures CSV data to Zorro’s T6 format.
Analysis of the CSV Data
Let’s take a look at the first few lines of the file, to see what we are parsing:
Date, Time, Open, High, Low, Close, Volume, NumberOfTrades, BidVolume, AskVolume
2008/11/26, 03:54:00, 848.25, 848.25, 848.25, 848.25, 1, 1, 0, 0
2008/11/26, 05:04:00, 846.50, 846.75, 846.50, 846.75, 2, 1, 0, 0
2008/11/26, 06:49:00, 843.25, 843.25, 843.25, 843.25, 5, 1, 0, 0
2008/11/26, 07:15:00, 844.00, 844.00, 844.00, 844.00, 1, 1, 0, 0
2008/11/26, 07:16:00, 844.00, 844.00, 844.00, 844.00, 1, 1, 0, 0
2008/11/26, 08:00:00, 846.75, 846.75, 846.75, 846.75, 1, 1, 0, 0
Any time that I am parsing from CSV to T6 format, I always start with Zorro’s CSVtoHistory template, but I would normally need to customize the CSV Format string to suit. As you can see, the purpose of the format string is to map all of the values into a T6 struct.
/*
typedef struct T6
{
DATE time;
float fHigh, fLow; // (f1,f2)
float fOpen, fClose; // (f3,f4)
float fVal, fVol; // optional data, like spread and volume (f5,f6)
} T6; // 6-stream tick, .t6 file content
*/
string Format = "+%Y/%m/%d%,%H:%M:%S,f3,f1,f2,f4,f6,f5";
But there is a problem, which I determined experimentally. If I use this format code with the CSV as shown, the minutes do not parse at all. (All of the other values parse correctly.)
I have hypothesized that the space character between the date and the time is causing problems for Zorro’s parser. Luckily, there is an easy workaround. Easy, if you know C anyways!
Modification of the CSV Data
My approach is to modify the source data so that there are no longer any space characters. I don’t really need the space characters at all, so good riddance!
Here is the code block:
#ifdef REMOVE_SPACES
// first, remove all spaces from the input csv, and overwrite the file (no need to keep original).
{
string original = file_content(InName);
if(!original){
printf("\nError, cannot read original file!");
return;
}
string output;
int i; // position for input
int j; // position for output
int len = strlen(original);
output = malloc(len);
if(!output){
printf("\nMalloc failed!");
return;
}
memset(output,0,len);
for(i=0; i< len; i++){
char ch = original[i];
switch(ch){
case ' ':
// do nothing
break;
default:
output[j] = ch;
j++;
}
}
file_write(InName, output, strlen(output));
}
#endif // REMOVE_SPACES
If you define REMOVE_SPACES at the beginning of your script, the code block will be activated. It will overwrite your CSV and make it look like this:
Date,Time,Open,High,Low,Close,Volume,NumberOfTrades,BidVolume,AskVolume
2008/11/26,03:54:00,848.25,848.25,848.25,848.25,1,1,0,0
2008/11/26,05:04:00,846.50,846.75,846.50,846.75,2,1,0,0
2008/11/26,06:49:00,843.25,843.25,843.25,843.25,5,1,0,0
2008/11/26,07:15:00,844.00,844.00,844.00,844.00,1,1,0,0
2008/11/26,07:16:00,844.00,844.00,844.00,844.00,1,1,0,0
2008/11/26,08:00:00,846.75,846.75,846.75,846.75,1,1,0,0
You can get the final script here. Let’s run it!
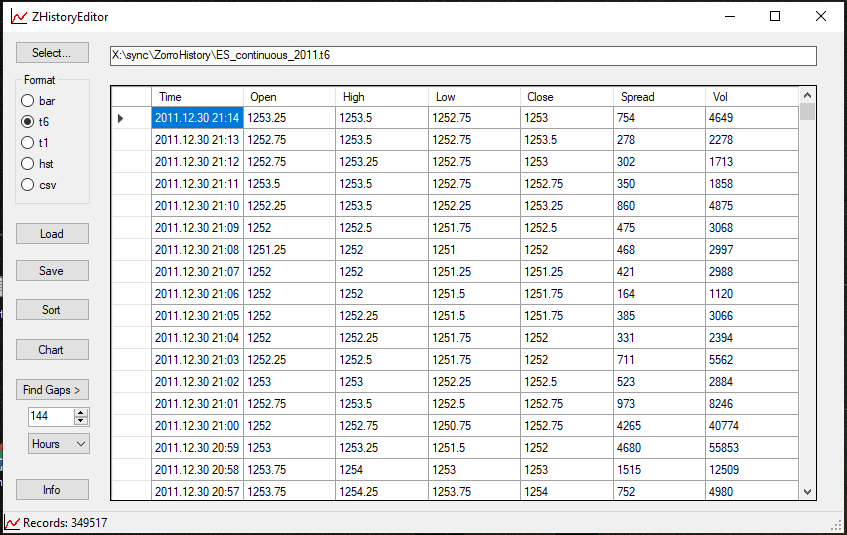
We can investigate the T6 file using the ZHistoryEditor tool, from the Zorro website.
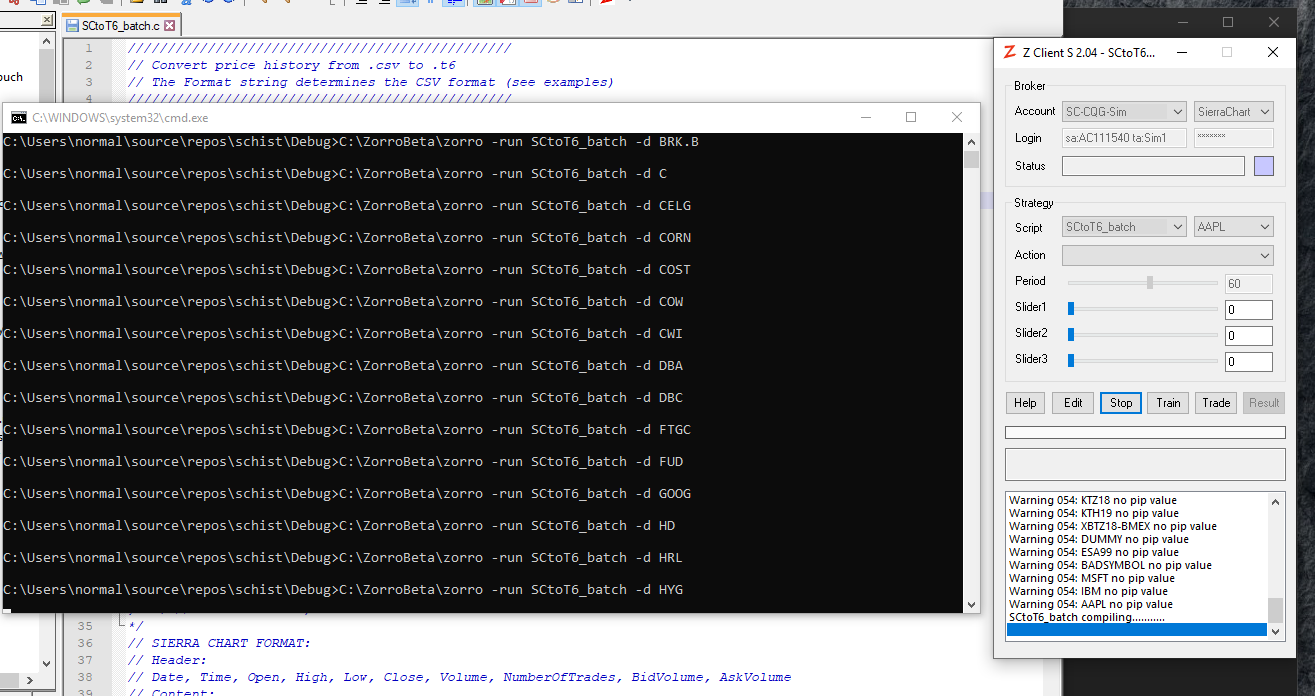
Batch T6 Conversions
Although I am not converting continuous futures in massive batches, I certainly am doing this with stocks. With minor modifications, I have been able to convert this script into a batch script. You can find the script here. I’ll let you figure out how it works.
Comments locked due to spam.
Thank You Andrew for grat howto. By the way, in Forum hast the SC plugin Version 9.2.4 but at GitHub 9.2.1. ?Is there a special reason why you don’t upgrade GitHub?
Ted, two reasons: 1) I have plans to overhaul it, and 2) it’s a low-priority because this project is not funded, and meanwhile I have deadlines to meet with my paid clients.
Anyways, I went ahead and updated the repository. Bon appetit.